比较对象:
- 华为 ExaGear
- MacOS 15上的Rosetta 2(part of GPTK2)
- Box64
- FEX-emu
- QEMU
- windows on arm Prsim
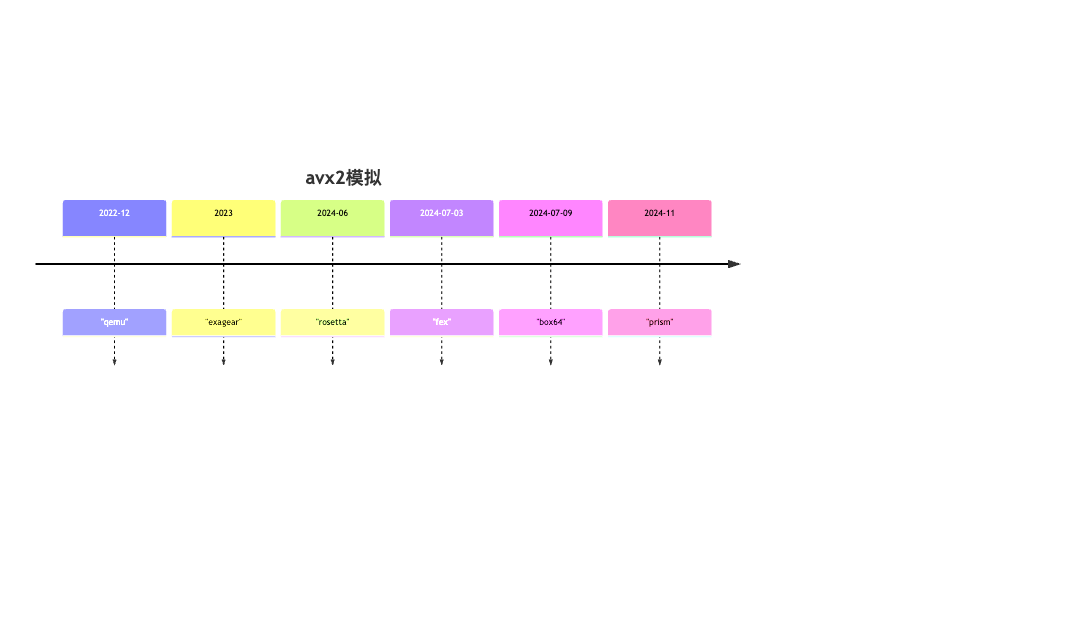
支持AVX2时间表
exagear
本文exagear测试版本是2.0.0.1, 最早支持时间未知,可以在https://mirrors.huaweicloud.com/kunpeng/archive/ExaGear/下载,最早的版本是20年 [ExaGear_V100R002C00.tar.gz]不支持avx2(https://mirrors.huaweicloud.com/kunpeng/archive/ExaGear/ExaGear_V100R002C00.tar.gz),猜测是22年到23年这个时间段支持了。
exagear不支持鲲鹏之外的cpu上运行,不然会提示Unsupported CPU,破解方法参考https://hu60.cn/q.php/bbs.topic.102147.html
sudo -i
# 破解 ubt_x32a64_al
f='/opt/exagear/bin/ubt_x32a64_al';
mv "$f" "$f.origin";
perl -pe 's/\x{02}\x{7C}\x{18}\x{53}(?!\x{1F}\x{5C})/\x{02}\x{09}\x{80}\x{D2}/g' < "$f.origin" > "$f";
chmod +x "$f";
# 破解 ubt_x64a64_al
f='/opt/exagear/bin/ubt_x64a64_al';
mv "$f" "$f.origin";
perl -pe 's/\x{02}\x{7C}\x{18}\x{53}(?!\x{1F}\x{5C})/\x{02}\x{09}\x{80}\x{D2}/g' < "$f.origin" > "$f";
chmod +x "$f";
box64
2024.7.9 https://github.com/ptitSeb/box64/releases/tag/v0.3.0
本文通过pi-labs进行部署
fex
2024.7.3 https://fex-emu.com/FEX-2407/
rosetta 2
2024.6.10 wwdc 2024
prism
2024.11.6 windows 11 canary https://blogs.windows.com/windows-insider/2024/11/06/announcing-windows-11-insider-preview-build-27744-canary-channel/)
qemu
2022.12.15 https://wiki.qemu.org/ChangeLog/7.2
测试版本
box64 --version
Dynarec for ARM64, with extension: ASIMD AES CRC32 PMULL ATOMICS SHA1 SHA2 PageSize:4096 Running on - with 2 Cores
Will use Hardware counter measured at 24.0 MHz emulating 3.0 GHz
Params database has 95 entries
Box64 with Dynarec v0.3.1 b46925e7 built on Nov 10 2024 06:21:12
exagear 2.0.0.1
prism build-27744
fex-emu:FEX-Emu (FEX-2410)
qemu:version 8.2.2 (Debian 1:8.2.2+ds-0ubuntu1.2)
gptk2:macOS15.1
AVX2吞吐量测试方法
计算原理解释
借用项目https://github.com/carlushuang/avx_flops
其中
#define AVX2_FMA_FP32_FLOP (10*2*8)
static void avx2_fma_fp32_kernel(uint64_t loop){
asm volatile(
" movq %0, %%rax \n"
" vxorps %%ymm0, %%ymm0, %%ymm0 \n"
" vxorps %%ymm1, %%ymm1, %%ymm1 \n"
" vxorps %%ymm2, %%ymm2, %%ymm2 \n"
" vxorps %%ymm3, %%ymm3, %%ymm3 \n"
" vxorps %%ymm4, %%ymm4, %%ymm4 \n"
" vxorps %%ymm5, %%ymm5, %%ymm5 \n"
" vxorps %%ymm6, %%ymm6, %%ymm6 \n"
" vxorps %%ymm7, %%ymm7, %%ymm7 \n"
" vxorps %%ymm8, %%ymm8, %%ymm8 \n"
" vxorps %%ymm9, %%ymm9, %%ymm9 \n"
"0: \n"
" vfmadd231ps %%ymm0, %%ymm0, %%ymm0 \n"
" vfmadd231ps %%ymm1, %%ymm1, %%ymm1 \n"
" vfmadd231ps %%ymm2, %%ymm2, %%ymm2 \n"
" vfmadd231ps %%ymm3, %%ymm3, %%ymm3 \n"
" vfmadd231ps %%ymm4, %%ymm4, %%ymm4 \n"
" vfmadd231ps %%ymm5, %%ymm5, %%ymm5 \n"
" vfmadd231ps %%ymm6, %%ymm6, %%ymm6 \n"
" vfmadd231ps %%ymm7, %%ymm7, %%ymm7 \n"
" vfmadd231ps %%ymm8, %%ymm8, %%ymm8 \n"
" vfmadd231ps %%ymm9, %%ymm9, %%ymm9 \n"
" subq $0x1, %%rax \n"
" jne 0b \n"
:
:"r"(loop)
: "ymm0","ymm1","ymm2","ymm3","ymm4",
"ymm5","ymm6","ymm7","ymm8","ymm9" );
}
#define AVX2_FMA_FP64_FLOP (10*2*4)
static void avx2_fma_fp64_kernel(uint64_t loop){
asm volatile(
" movq %0, %%rax \n"
" vxorpd %%ymm0, %%ymm0, %%ymm0 \n"
" vxorpd %%ymm1, %%ymm1, %%ymm1 \n"
" vxorpd %%ymm2, %%ymm2, %%ymm2 \n"
" vxorpd %%ymm3, %%ymm3, %%ymm3 \n"
" vxorpd %%ymm4, %%ymm4, %%ymm4 \n"
" vxorpd %%ymm5, %%ymm5, %%ymm5 \n"
" vxorpd %%ymm6, %%ymm6, %%ymm6 \n"
" vxorpd %%ymm7, %%ymm7, %%ymm7 \n"
" vxorpd %%ymm8, %%ymm8, %%ymm8 \n"
" vxorpd %%ymm9, %%ymm9, %%ymm9 \n"
"0: \n"
" vfmadd231pd %%ymm0, %%ymm0, %%ymm0 \n"
" vfmadd231pd %%ymm1, %%ymm1, %%ymm1 \n"
" vfmadd231pd %%ymm2, %%ymm2, %%ymm2 \n"
" vfmadd231pd %%ymm3, %%ymm3, %%ymm3 \n"
" vfmadd231pd %%ymm4, %%ymm4, %%ymm4 \n"
" vfmadd231pd %%ymm5, %%ymm5, %%ymm5 \n"
" vfmadd231pd %%ymm6, %%ymm6, %%ymm6 \n"
" vfmadd231pd %%ymm7, %%ymm7, %%ymm7 \n"
" vfmadd231pd %%ymm8, %%ymm8, %%ymm8 \n"
" vfmadd231pd %%ymm9, %%ymm9, %%ymm9 \n"
" subq $0x1, %%rax \n"
" jne 0b \n"
:
:"r"(loop)
: "ymm0","ymm1","ymm2","ymm3","ymm4",
"ymm5","ymm6","ymm7","ymm8","ymm9" );
}
计算公式为

其中总FLOPs为 loop * 每次循环执行指令数,这里是AVX2_FMA_FP32_FLOP为160次
FMA_FP32(单精度)每次循环迭代的浮点运算次数:10(指令) * 2(运算) * 8(数据) = 160 次,同理,FMA_FP64(双精度)是10 * 2* 4。
其中10条指令是在每次循环迭代中,有10条 vfmadd231ps 指令,2次运算( *= Fused Multiply-Add),8个数据是指每个 ymm 寄存器包含8个单精度浮点数,或者4个双精度浮点数,而前面的vfmadd231ps是指Fused Multiply-Add of Packed Single- Precision Floating-Point Values,计算8个单精度浮点数,后面的vfmadd231pd是指Fused Multiply-Add of Packed Double- Precision Floating-Point Values,计算4个双精度浮点数。
总循环次数定义为#define LOOP 0xc0000000
所以总FLOPs为 160 * 3,221,225,472 = 515,396,075,520 次,然后再除以执行时间 * 10 * 9即为 GFLOPs
Windows转译层代码
MSVC并不支持上述的汇编写法,用intrinsics写
#define AVX2_FMA_FP32_FLOP (10*2*8)
static void avx2_fma_fp32_kernel(uint64_t loop) {
// Initialize vectors to zero
__m256 ymm0 = _mm256_setzero_ps();
__m256 ymm1 = _mm256_setzero_ps();
__m256 ymm2 = _mm256_setzero_ps();
__m256 ymm3 = _mm256_setzero_ps();
__m256 ymm4 = _mm256_setzero_ps();
__m256 ymm5 = _mm256_setzero_ps();
__m256 ymm6 = _mm256_setzero_ps();
__m256 ymm7 = _mm256_setzero_ps();
__m256 ymm8 = _mm256_setzero_ps();
__m256 ymm9 = _mm256_setzero_ps();
// Main computation loop
while (loop--) {
// vfmadd231ps: multiply and add - (a * b) + c
ymm0 = _mm256_fmadd_ps(ymm0, ymm0, ymm0);
ymm1 = _mm256_fmadd_ps(ymm1, ymm1, ymm1);
ymm2 = _mm256_fmadd_ps(ymm2, ymm2, ymm2);
ymm3 = _mm256_fmadd_ps(ymm3, ymm3, ymm3);
ymm4 = _mm256_fmadd_ps(ymm4, ymm4, ymm4);
ymm5 = _mm256_fmadd_ps(ymm5, ymm5, ymm5);
ymm6 = _mm256_fmadd_ps(ymm6, ymm6, ymm6);
ymm7 = _mm256_fmadd_ps(ymm7, ymm7, ymm7);
ymm8 = _mm256_fmadd_ps(ymm8, ymm8, ymm8);
ymm9 = _mm256_fmadd_ps(ymm9, ymm9, ymm9);
}
// Prevent the compiler from optimizing away the computation
// by making the results volatile
volatile float result;
result = _mm256_cvtss_f32(ymm0);
result = _mm256_cvtss_f32(ymm1);
result = _mm256_cvtss_f32(ymm2);
result = _mm256_cvtss_f32(ymm3);
result = _mm256_cvtss_f32(ymm4);
result = _mm256_cvtss_f32(ymm5);
result = _mm256_cvtss_f32(ymm6);
result = _mm256_cvtss_f32(ymm7);
result = _mm256_cvtss_f32(ymm8);
result = _mm256_cvtss_f32(ymm9);
}
#define AVX2_FMA_FP64_FLOP (10*2*4)
static void avx2_fma_fp64_kernel(uint64_t loop) {
// Initialize vectors to zero
__m256d ymm0 = _mm256_setzero_pd();
__m256d ymm1 = _mm256_setzero_pd();
__m256d ymm2 = _mm256_setzero_pd();
__m256d ymm3 = _mm256_setzero_pd();
__m256d ymm4 = _mm256_setzero_pd();
__m256d ymm5 = _mm256_setzero_pd();
__m256d ymm6 = _mm256_setzero_pd();
__m256d ymm7 = _mm256_setzero_pd();
__m256d ymm8 = _mm256_setzero_pd();
__m256d ymm9 = _mm256_setzero_pd();
// Main computation loop
while (loop--) {
// vfmadd231pd: multiply and add - (a * b) + c
ymm0 = _mm256_fmadd_pd(ymm0, ymm0, ymm0);
ymm1 = _mm256_fmadd_pd(ymm1, ymm1, ymm1);
ymm2 = _mm256_fmadd_pd(ymm2, ymm2, ymm2);
ymm3 = _mm256_fmadd_pd(ymm3, ymm3, ymm3);
ymm4 = _mm256_fmadd_pd(ymm4, ymm4, ymm4);
ymm5 = _mm256_fmadd_pd(ymm5, ymm5, ymm5);
ymm6 = _mm256_fmadd_pd(ymm6, ymm6, ymm6);
ymm7 = _mm256_fmadd_pd(ymm7, ymm7, ymm7);
ymm8 = _mm256_fmadd_pd(ymm8, ymm8, ymm8);
ymm9 = _mm256_fmadd_pd(ymm9, ymm9, ymm9);
}
// Prevent the compiler from optimizing away the computation
// by making the results volatile
volatile double result;
result = _mm256_cvtsd_f64(ymm0);
result = _mm256_cvtsd_f64(ymm1);
result = _mm256_cvtsd_f64(ymm2);
result = _mm256_cvtsd_f64(ymm3);
result = _mm256_cvtsd_f64(ymm4);
result = _mm256_cvtsd_f64(ymm5);
result = _mm256_cvtsd_f64(ymm6);
result = _mm256_cvtsd_f64(ymm7);
result = _mm256_cvtsd_f64(ymm8);
result = _mm256_cvtsd_f64(ymm9);
}
_mm256_setzero_ps替代vxorpd来置0,_mm256_fmadd_ps来替代vfmadd231ps,_mm256_fmadd_pd来替代vfmadd231pd。
测试机器
M1 Pro Macbook Pro 2021,MacOS15
M4 Mac mini 2024,MacOS15
Windows dev kit 2023
miniforums 790s7
alibaba workspace 黄金版 经济版 ubuntu 20.04
其中FEX/Qemu/box64的操作系统为ubuntu 24.04 LTS
Prsim的操作系统为Windows 11 27744.1000
AVX2指令集探测方法
全平台:https://github.com/klauspost/cpuid/releases/tag/v2.2.9
MacOS:
arch -x86_64 sysctl -a | grep machdep.cpu.features
Windows:
CoreInfo:https://learn.microsoft.com/en-us/sysinternals/downloads/coreinfo
https://learn.microsoft.com/en-us/cpp/intrinsics/cpuid-cpuidex?view=msvc-170
Linux:lscpu
指令集测试结果
| 测试平台 | AVX2 |
|---|---|
| Rosetta2 | x |
| Rosetta2 + crossover | |
| Linux rosetta | x |
| Linux QEMU | |
| Linux exagear | x |
| Linux Box64 | |
| Linux FEX | |
| Windows Prsim | |
| Linux QEMU + crossover | |
| Linux exagear + crossover | x |
| Linux Box64 Wine | |
| Linux Fex Crossover | |
| Linux x86 native |
吞吐量测试结果
| 测试平台 | fp32(gflops) | fp64(gflops) |
|---|---|---|
| M1 Rosetta2 | 32.90 | 16.43 |
| M1 Rosetta2 + crossover | 34.66 | 16.79 |
| M4 Rosetta2 | 49.18 | 24.34 |
| xeon linux | 82.25 | 43.83 |
| M1 PD Linux qemu | 0.47 | 0.42 |
| M1 PD Linux box64 | 96.76 | 48.73 |
| M1 PD exagear | 38.37 | 17.70 |
| M1 PD prism | 37.96 | 19.59 |
| M1 PD FEX | 45.92 | 23.30 |
| M1 PD FEX crossover | 44.8 | 22.62 |
| M1 PD box64 wine | 44.5 | 21.95 |
| M1 PD exagear crossover | 38.74 | 19.31 |
| M1 PD qemu crossover | 0.6 | 0.5 |
| 8cx gen3 | 29.47 | 14.70 |
| 7940hx | 148.10 | 79.70 |
| i7 11800h | 68.10 | 34.93 |
| n100 | 51.33 | 26.21 |
| Xeon windows | 80.55 | 41.39 |
M1 PD box64可能是测试问题,数值异常,反复测试都是这个结果,但是转译win32后正常
测试视频:https://www.bilibili.com/video/BV1DeUYYzEkk/